
{kind=link}
I am a Master's student in the College of Mechatronics and Control Engineering at Shenzhen University. My research areas include Text-to-3D generation, diffusion models, hypergraph neural networks (HGNN), and LoRA fine-tuning. I focus on developing parameter-efficient fine-tuning strategies and hypergraph-based architectures to advance multimodal learning and high-fidelity 3D content generation.
My academic excellence has been recognized with several distinctions, including being named an 🏆 Outstanding Graduate of Shenzhen University (2025, awarded to 333 out of 5,208 graduates) and receiving the 🏆 Bachelor of Honor from the School of Mechatronics and Control Engineering (2025), through sustained academic leadership, service, and interdisciplinary innovation.
Research Interests
- Text-to-3D Generation
- Diffusion Models
- Multimodal Learning
- Hypergraph Neural Networks
- LoRA Fine-tuning
News
- 2026.06: 🎉 One paper has been accepted to the European Conference on Computer Vision (ECCV 2026)!
- 2026.04: 🎉 One paper has been accepted to the International Joint Conference on Artificial Intelligence (IJCAI 2026)!
- 2026.02: 🎉 One paper has been accepted to the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026) Findings!
- 2025.05: 🎉 One paper has been accepted to the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2025)!
Education
-
 Shenzhen University Sep. 2025 - presentCollege of Mechatronics and Control Engineering
Shenzhen University Sep. 2025 - presentCollege of Mechatronics and Control Engineering
M.S. Student -
Shenzhen University Sep. 2021 - Jul. 2025College of Mechatronics and Control Engineering
B.S. Student
Academic Service
- Reviewer of International Conference on Computer Vision. ICCV 2025
- Reviewer of European Conference on Computer Vision. ECCV 2026
- Reviewer of Association for the Advancement of Artificial Intelligence. AAAI 2026
- Reviewer of The IEEE/CVF Conference on Computer Vision and Pattern Recognition. CVPR 2026
Honors and Awards
- 2026: 🏆 Graduate Academic Scholarship, Special Prize
- 2025: 🏆 Outstanding Graduate, Shenzhen University
- 2025: 🏆 Bachelor of Honor, School of Mechatronics and Control Engineering
- 2024: 🥈 Second Prize, 15th Blue Bridge Cup Guangdong Regional Competition (Embedded Design & Development, University Group)
- 2023: 🎖️ Outstanding Communist Youth League Member
- 2024: 🥇 First Prize, Public Welfare Star (Academic Year 2023-2024)
- 2024: 🏅 National Encouragement Scholarship (Academic Year 2023-2024)
- 2024: 🥉 Third Prize, Academic Star (Academic Year 2023-2024)
- 2023: 🏅 National Encouragement Scholarship (Academic Year 2022-2023)
- 2023: 🥈 Second Prize, Academic Star (Academic Year 2022-2023)
- 2022: 🥈 Second Prize, Academic Star (Academic Year 2021-2022)
Selected Publications
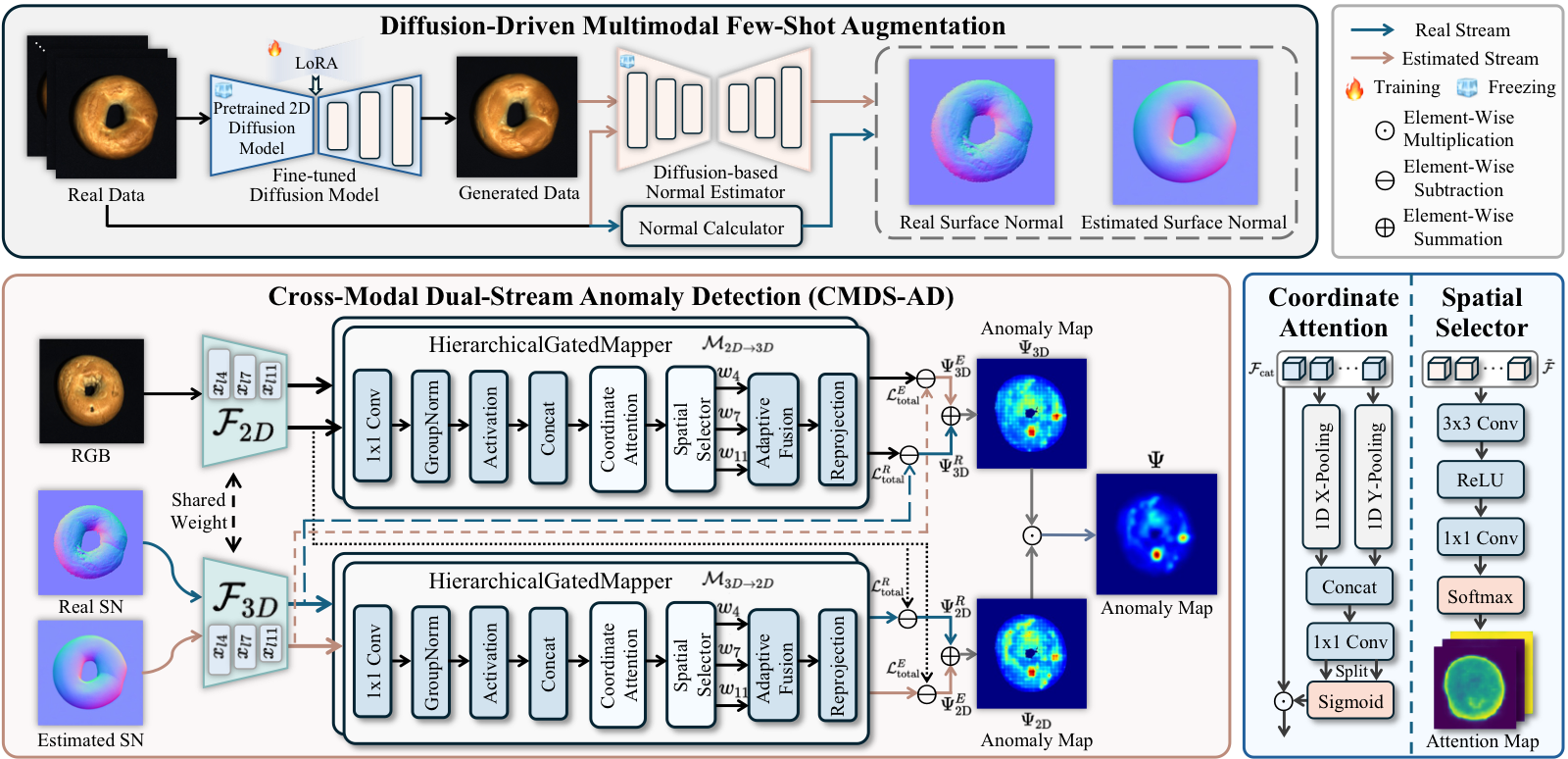
CMDS-AD: Cross-Modal Dual-Stream Decoupling for Few-Shot Anomaly Detection
Few-shot anomaly detection remains challenging due to limited training data. Multi-modal anomaly detection (MAD) offers a viable solution by leveraging 3D geometric cues to enrich 2D RGB representations and compensate for this scarcity. However, existing MAD methods apply spatially uniform feature processing, conflating stable macroscopic structures with high-frequency localized defect signals and thereby exacerbating cross-modal misalignment and false-positive rates. To overcome this, we present CMDS-AD, a Cross-Modal Dual-Stream Anomaly Detection framework. A LoRA-guided diffusion model generates diverse RGB samples to mitigate extreme data scarcity. For 3D normal augmentation, we employ a pre-trained diffusion model as a normal estimator. This estimator inherently acts as a non-linear low-pass filter, directly extracting low-frequency normal representations from RGB inputs. This establishes an auxiliary estimated stream of purely low-frequency information, anchoring robust structural templates and assisting the uncompressed real stream to precisely isolate micro-defects. A Coordinate-Aware Hierarchical Feature Mapper adaptively aligns cross-modal semantics, while a multiplicative scoring mechanism filters modality-specific noise. Under the extreme 1-shot setting, CMDS-AD achieves absolute performance gains of 5.7% (I-AUROC) and 2.0% (AUPRO) on MVTec 3D-AD, alongside 7.7% and 5.6% improvements on EyeCandies, establishing a new state of the art.
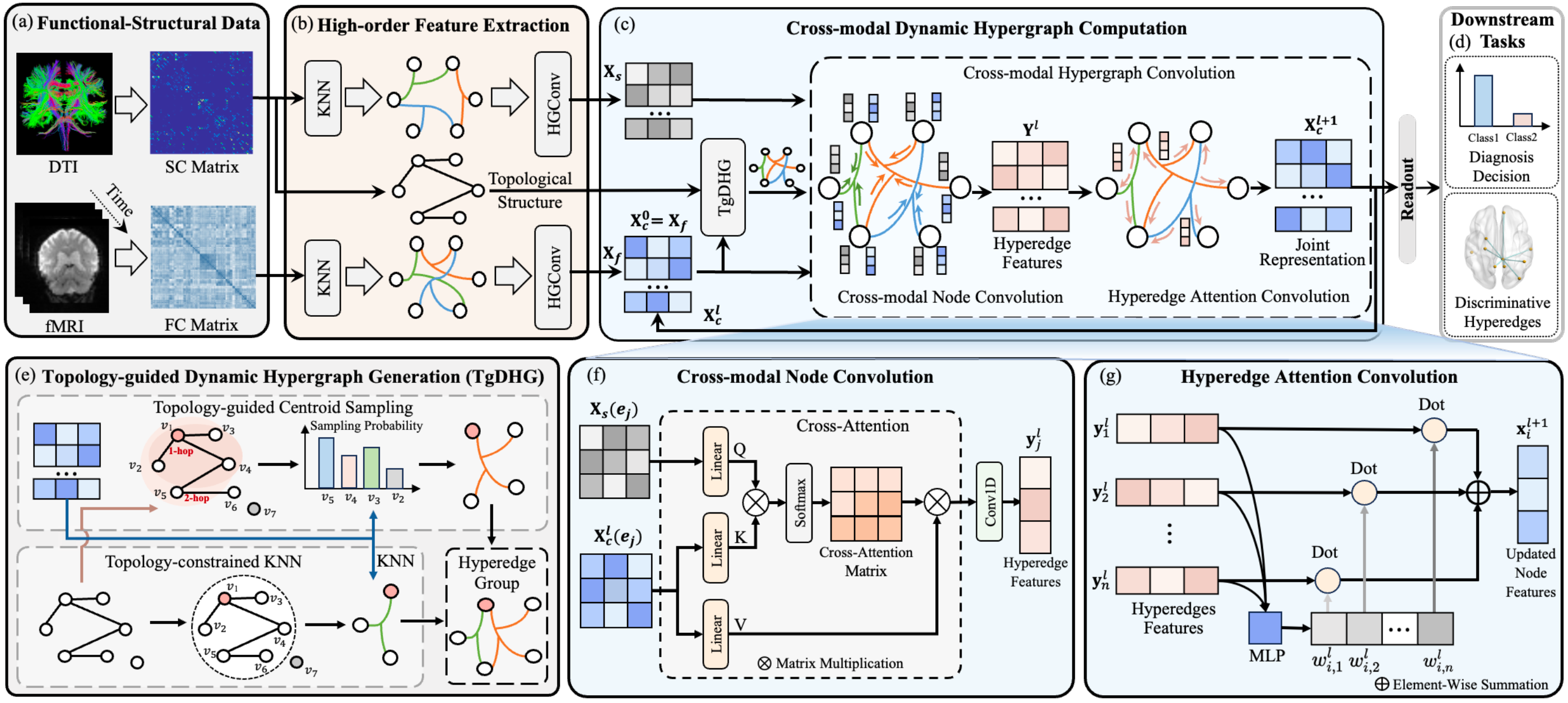
Cross-Modal Dynamic Hypergraph Computation via Functional-Structural Brain Network for Brain Disease Diagnosis
Cross-modal brain networks offer complementary functional and structural views for understanding inter-regional connectivity and diagnosing brain diseases, yet existing methods often underuse their joint topology and high-order associations. This paper proposes Cross-Modal Dynamic Hypergraph Computation (CDHGC), a framework that learns topology-guided high-order correlations in functional-structural brain networks. CDHGC first generates and dynamically optimizes topology-aware hypergraphs to reveal latent cross-modal relationships, then performs cross-modal hypergraph convolution with attention-based message passing to produce joint representations. Experiments on ADNI and ABIDE show that CDHGC surpasses state-of-the-art methods, while interpretability analysis identifies multimodal biomarkers related to brain disorders.
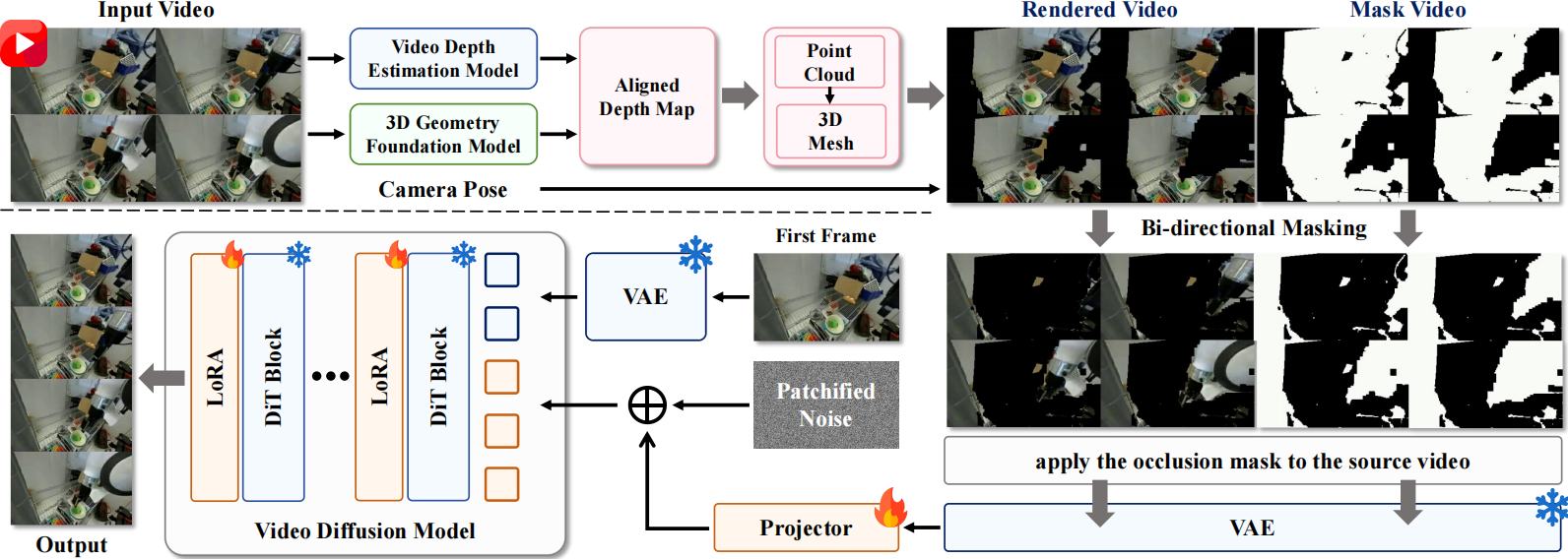
Beyond Viewpoint Generalization: What Multi-View Demonstrations Offer and How to Synthesize Them for Robot Manipulation?
Does multi-view demonstration truly improve robot manipulation, or merely enhance cross-view robustness? This paper presents a systematic study quantifying the performance gains, scaling behavior, and underlying mechanisms of multi-view data for robot manipulation. Controlled experiments show that, under both fixed and randomized backgrounds, multi-view demonstrations consistently improve single-view policy success and generalization. Motivated by the importance of multi-view data and its scarcity in large-scale robotic datasets, the paper further proposes RoboNVS, a geometry-aware self-supervised framework that synthesizes novel-view videos from monocular inputs, and shows that the generated data consistently improves downstream policies in both simulation and real-world environments.
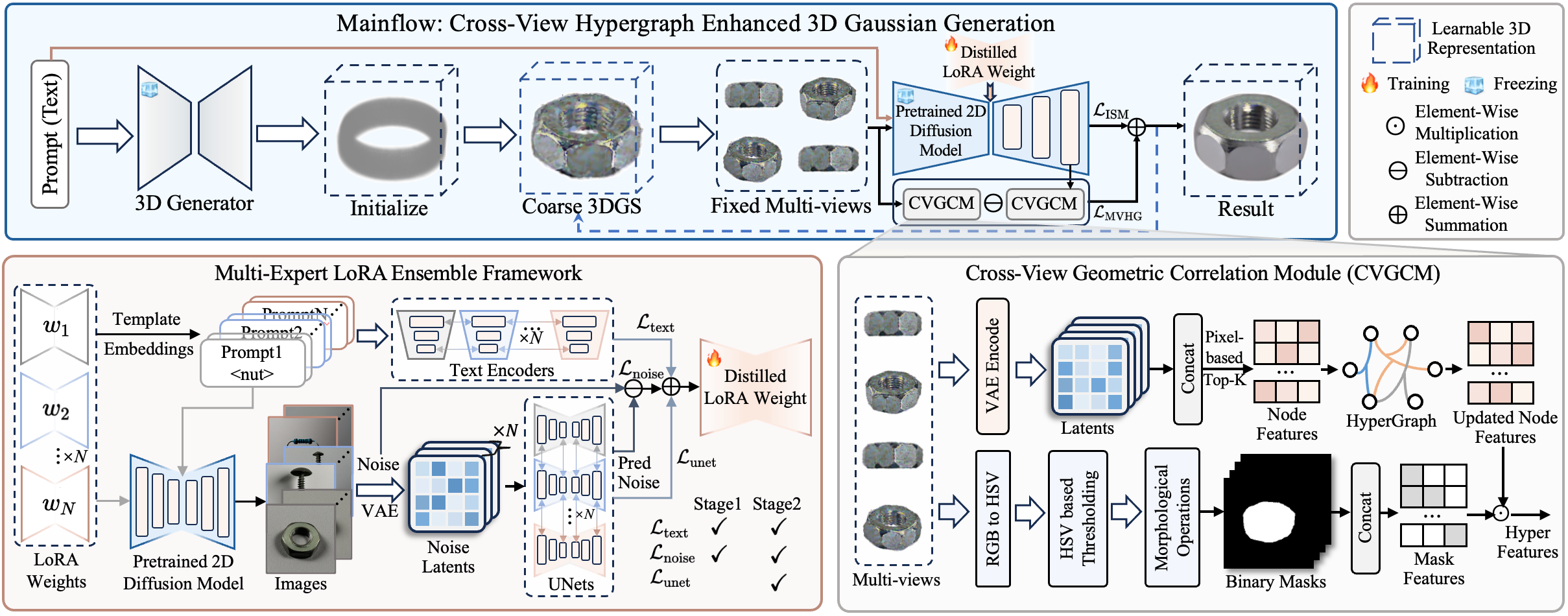
ForgeDreamer: Industrial Text-to-3D Generation with Multi-Expert LoRA and Cross-View Hypergraph
Current text-to-3D generation methods excel in natural scenes but struggle with industrial applications due to two critical limitations: domain adaptation challenges, where conventional LoRA fusion causes knowledge interference across categories, and geometric reasoning deficiencies, where pairwise consistency constraints fail to capture higher-order structural dependencies essential for precision manufacturing. We propose a novel framework named ForgeDreamer that addresses both challenges through two key innovations. First, we introduce a Multi-Expert LoRA Ensemble mechanism that consolidates multiple category-specific LoRA models into a unified representation, achieving superior cross-category generalization while eliminating knowledge interference. Second, building on enhanced semantic understanding, we develop a Cross-View Hypergraph Geometric Enhancement approach that captures structural dependencies spanning multiple viewpoints simultaneously. These components work synergistically: improved semantic understanding enables more effective geometric reasoning, while hypergraph modeling ensures manufacturing-level consistency. Extensive experiments on a custom industrial dataset demonstrate superior semantic generalization and enhanced geometric fidelity compared to state-of-the-art approaches.
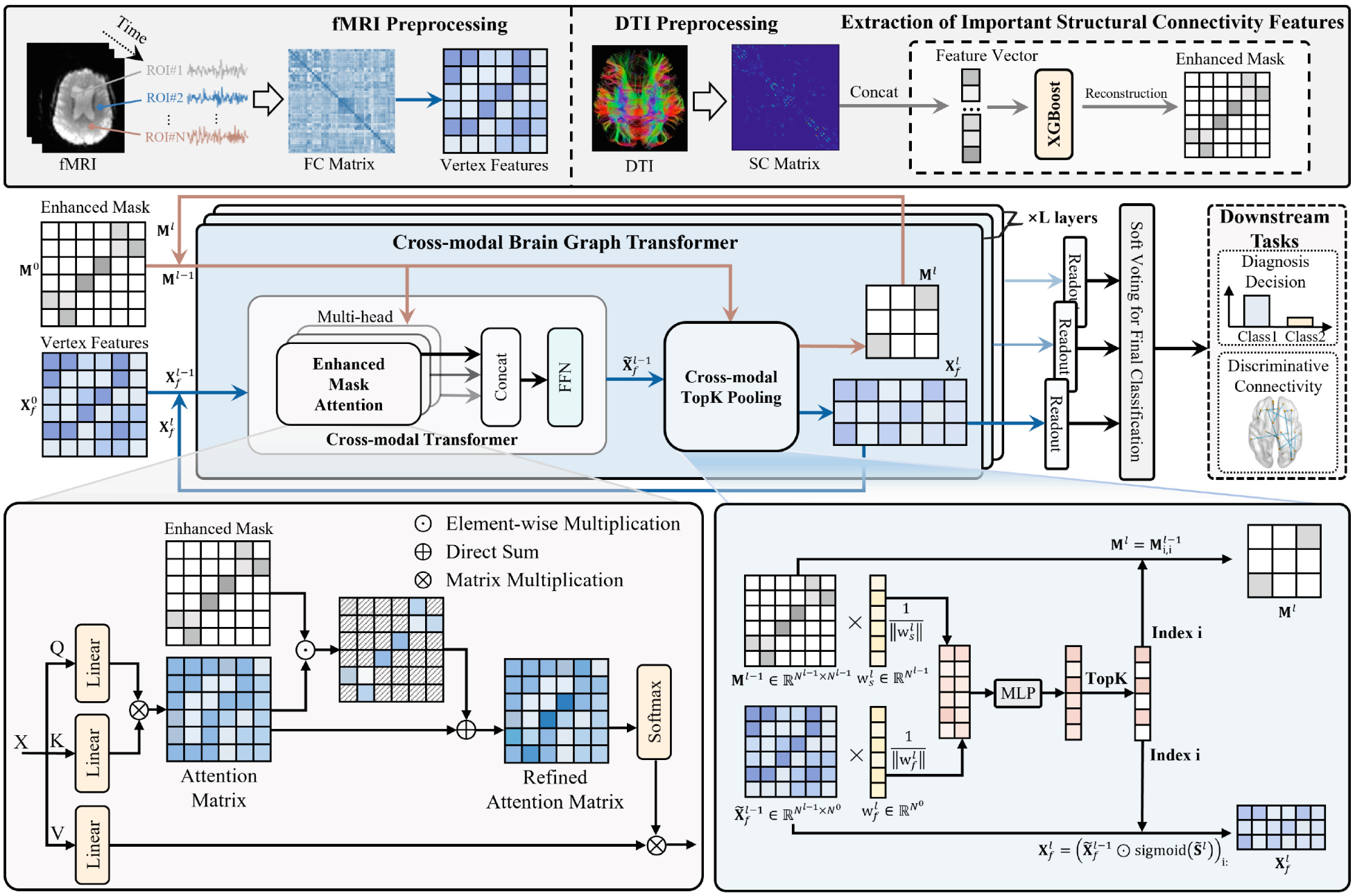
Cross-Modal Brain Graph Transformer via Function-Structure Connectivity Network for Brain Disease Diagnosis
Multi-modal brain networks represent the complex connectivity between different brain regions from both functional and structural perspectives, which is of great significance for brain disease diagnosis. However, existing methods are limited to information fusion in the feature dimension, failing to fully exploit the complementary information between functional and structural connectivity networks. To address these issues, this paper proposes a cross-modal brain graph transformer (CBGT) method for brain disease diagnosis, which also provides an in-depth analysis of coupled function-structure connectivity networks. Specifically, CBGT consists of two main modules: the cross-modal Transformer module enhances the attention mechanism by utilizing structural connectivity features extracted through machine learning methods, capturing long-range dependencies in the cross-modal brain network. The cross-modal topK pooling module combines information from both functional and structural connectivity networks to select significant regions of interest (ROIs) during the reconstruction of the pooled graph, aiming to retain as much effective information as possible. Experiments conducted on the ABIDE and ADNI datasets demonstrate that the proposed method outperforms state-of-the-art approaches. Interpretation analysis reveals that the proposed method can identify multi-modal biomarkers associated with brain diseases.