
{kind=link}
我目前是深圳大学机电与控制工程学院硕士研究生。 我的研究方向包括 文生 3D 生成、扩散模型、 超图神经网络(HGNN) 和 LoRA 微调。 我主要关注参数高效微调策略与基于超图的网络架构,以推进多模态学习与高保真 3D 内容生成。
在学业方面,我曾获得多项荣誉,包括 🏆 深圳大学优秀毕业生 (2025 年,5208 名毕业生中仅 333 人获评)以及 🏆 机电与控制工程学院荣誉学士(2025 年), 也体现了我在学术引领、服务与跨学科创新方面的持续投入。
研究方向
- 文生 3D 生成
- 扩散模型
- 多模态学习
- 超图神经网络
- LoRA 微调
最新动态
- 2026.06: 🎉 一篇论文被欧洲计算机视觉会议(ECCV 2026)录用!
- 2026.04: 🎉 一篇论文被国际人工智能联合会议(IJCAI 2026)录用!
- 2026.02: 🎉 一篇论文被 IEEE/CVF 计算机视觉与模式识别会议(CVPR 2026)Findings 录用!
- 2025.05: 🎉 一篇论文被医学图像计算与计算机辅助干预国际会议(MICCAI 2025)录用!
教育经历
-
 深圳大学 2025年9月 - 至今机电与控制工程学院
深圳大学 2025年9月 - 至今机电与控制工程学院
硕士研究生 -
深圳大学 2021年9月 - 2025年7月机电与控制工程学院
学士
学术服务
- 国际计算机视觉大会 审稿人 ICCV 2025
- 欧洲计算机视觉会议 审稿人 ECCV 2026
- AAAI 人工智能大会 审稿人 AAAI 2026
- IEEE/CVF 计算机视觉与模式识别会议 审稿人 CVPR 2026
荣誉奖励
- 2026: 🏆 研究生学业奖学金特等奖
- 2025: 🏆 深圳大学优秀毕业生
- 2025: 🏆 机电与控制工程学院荣誉学士
- 2024: 🥈 第十五届蓝桥杯广东赛区二等奖(嵌入式设计与开发大学组)
- 2023: 🎖️ 优秀共青团员
- 2024: 🥇 公益之星一等奖(2023-2024学年)
- 2024: 🏅 国家励志奖学金(2023-2024学年)
- 2024: 🥉 学习之星三等奖(2023-2024学年)
- 2023: 🏅 国家励志奖学金(2022-2023学年)
- 2023: 🥈 学习之星二等奖(2022-2023学年)
- 2022: 🥈 学习之星二等奖(2021-2022学年)
代表性论文
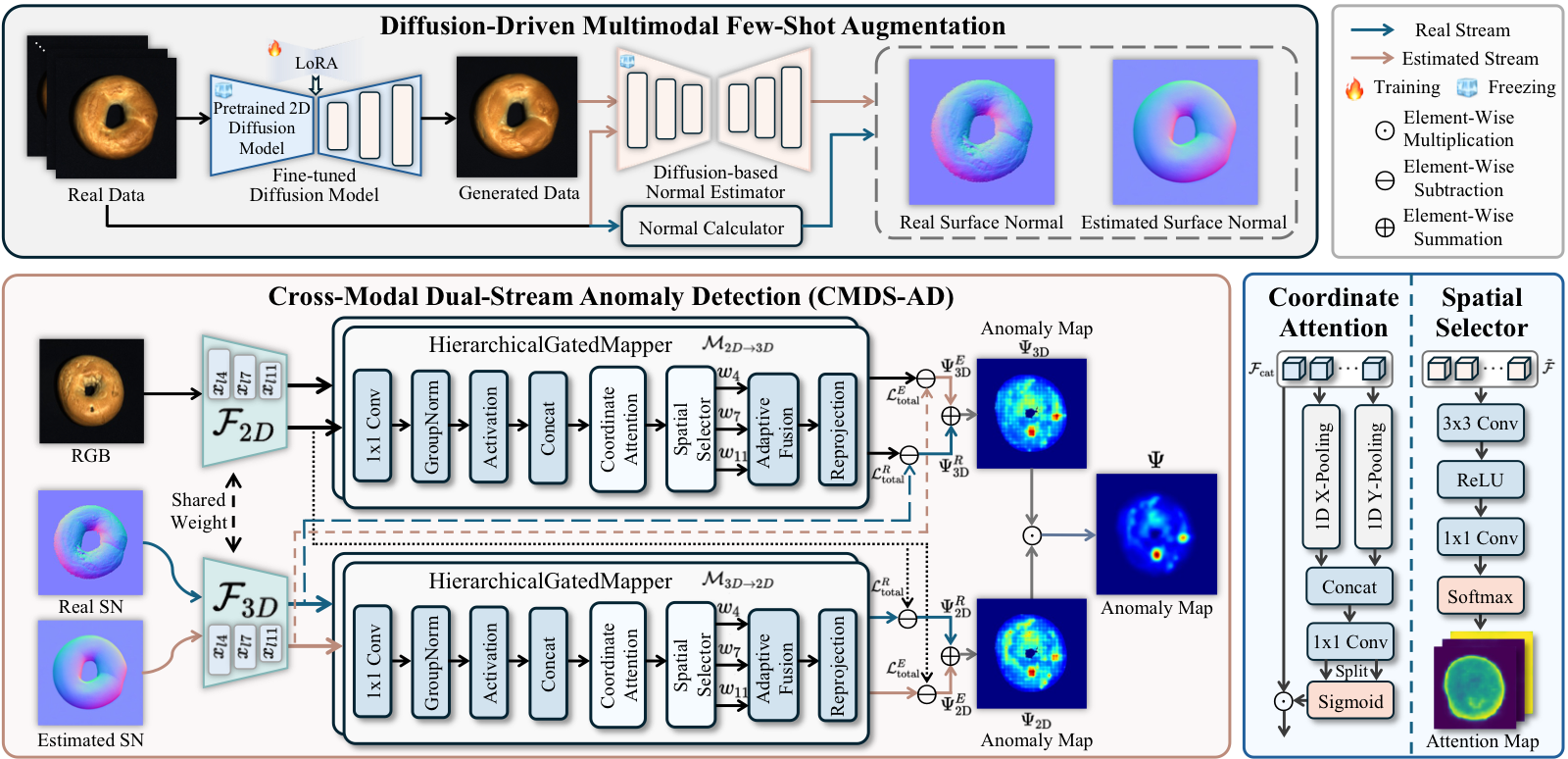
CMDS-AD: Cross-Modal Dual-Stream Decoupling for Few-Shot Anomaly Detection
Few-shot anomaly detection remains challenging due to limited training data. Multi-modal anomaly detection (MAD) offers a viable solution by leveraging 3D geometric cues to enrich 2D RGB representations and compensate for this scarcity. However, existing MAD methods apply spatially uniform feature processing, conflating stable macroscopic structures with high-frequency localized defect signals and thereby exacerbating cross-modal misalignment and false-positive rates. To overcome this, we present CMDS-AD, a Cross-Modal Dual-Stream Anomaly Detection framework. A LoRA-guided diffusion model generates diverse RGB samples to mitigate extreme data scarcity. For 3D normal augmentation, we employ a pre-trained diffusion model as a normal estimator. This estimator inherently acts as a non-linear low-pass filter, directly extracting low-frequency normal representations from RGB inputs. This establishes an auxiliary estimated stream of purely low-frequency information, anchoring robust structural templates and assisting the uncompressed real stream to precisely isolate micro-defects. A Coordinate-Aware Hierarchical Feature Mapper adaptively aligns cross-modal semantics, while a multiplicative scoring mechanism filters modality-specific noise. Under the extreme 1-shot setting, CMDS-AD achieves absolute performance gains of 5.7% (I-AUROC) and 2.0% (AUPRO) on MVTec 3D-AD, alongside 7.7% and 5.6% improvements on EyeCandies, establishing a new state of the art.
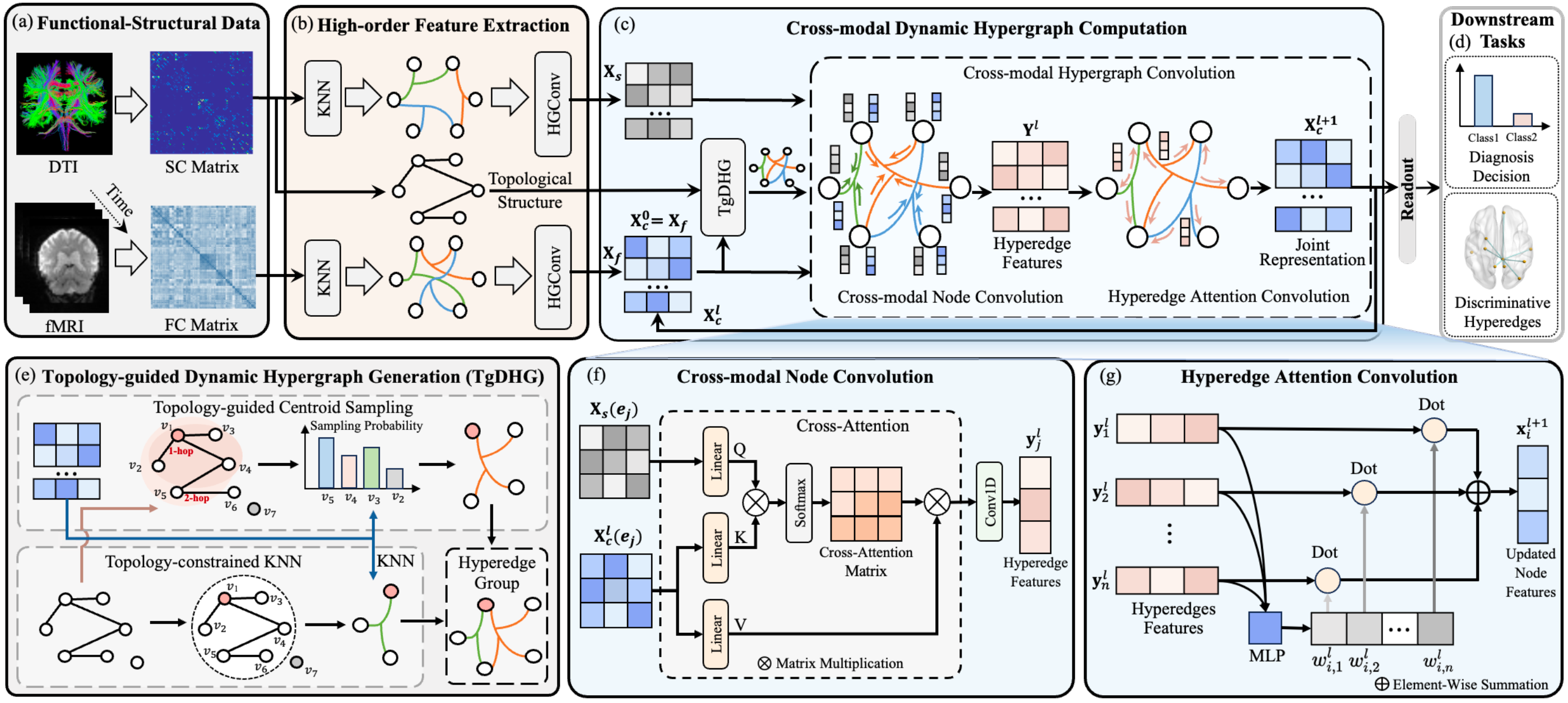
Cross-Modal Dynamic Hypergraph Computation via Functional-Structural Brain Network for Brain Disease Diagnosis
Cross-modal brain networks offer complementary functional and structural views for understanding inter-regional connectivity and diagnosing brain diseases, yet existing methods often underuse their joint topology and high-order associations. This paper proposes Cross-Modal Dynamic Hypergraph Computation (CDHGC), a framework that learns topology-guided high-order correlations in functional-structural brain networks. CDHGC first generates and dynamically optimizes topology-aware hypergraphs to reveal latent cross-modal relationships, then performs cross-modal hypergraph convolution with attention-based message passing to produce joint representations. Experiments on ADNI and ABIDE show that CDHGC surpasses state-of-the-art methods, while interpretability analysis identifies multimodal biomarkers related to brain disorders.
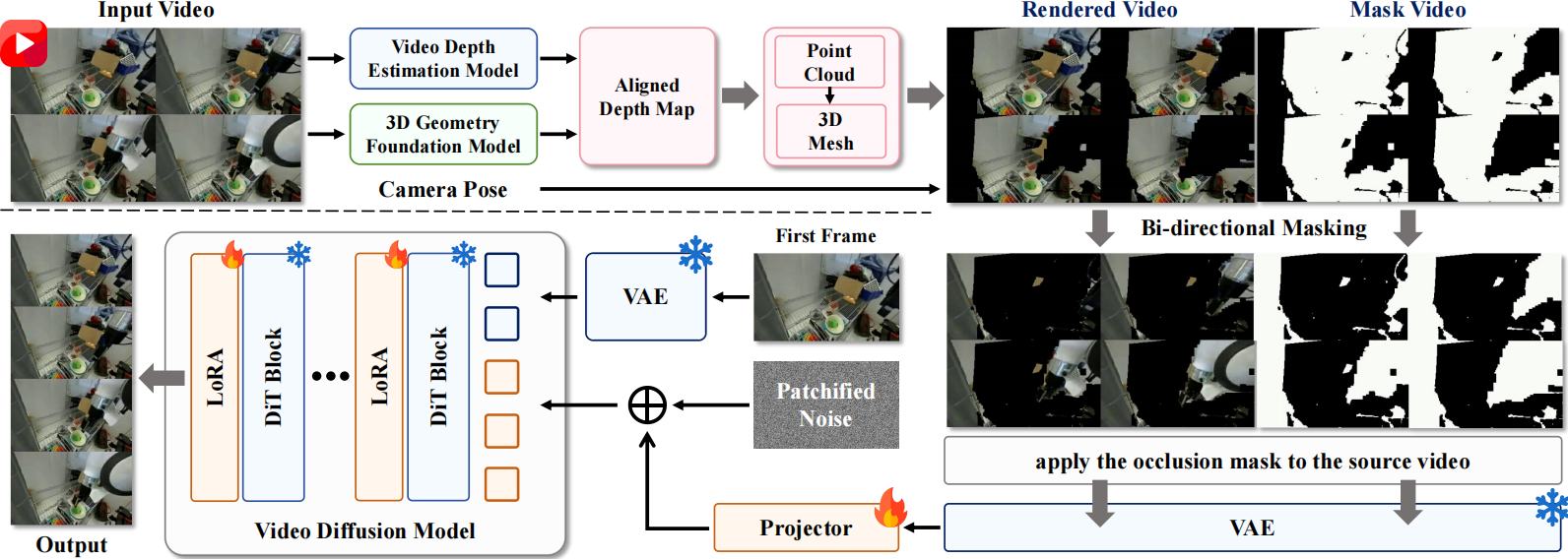
Beyond Viewpoint Generalization: What Multi-View Demonstrations Offer and How to Synthesize Them for Robot Manipulation?
Does multi-view demonstration truly improve robot manipulation, or merely enhance cross-view robustness? This paper presents a systematic study quantifying the performance gains, scaling behavior, and underlying mechanisms of multi-view data for robot manipulation. Controlled experiments show that, under both fixed and randomized backgrounds, multi-view demonstrations consistently improve single-view policy success and generalization. Motivated by the importance of multi-view data and its scarcity in large-scale robotic datasets, the paper further proposes RoboNVS, a geometry-aware self-supervised framework that synthesizes novel-view videos from monocular inputs, and shows that the generated data consistently improves downstream policies in both simulation and real-world environments.
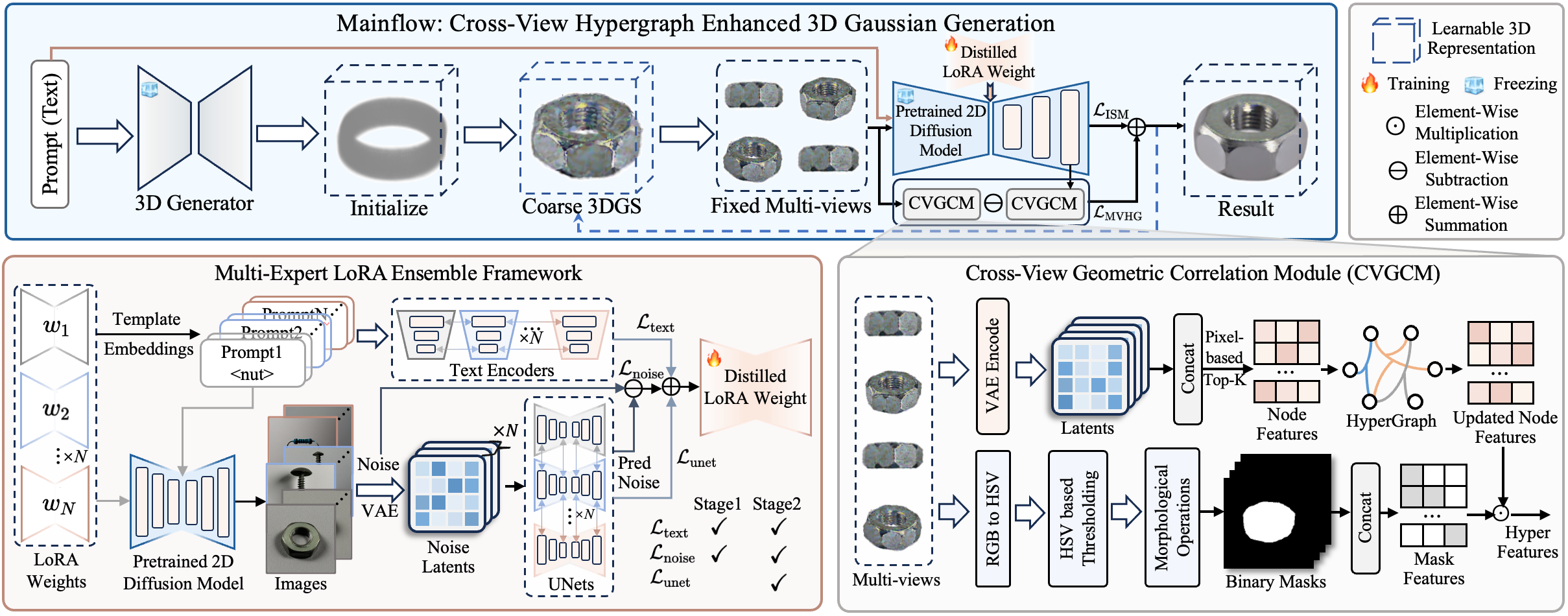
ForgeDreamer: Industrial Text-to-3D Generation with Multi-Expert LoRA and Cross-View Hypergraph
Current text-to-3D generation methods excel in natural scenes but struggle with industrial applications due to two critical limitations: domain adaptation challenges, where conventional LoRA fusion causes knowledge interference across categories, and geometric reasoning deficiencies, where pairwise consistency constraints fail to capture higher-order structural dependencies essential for precision manufacturing. We propose a novel framework named ForgeDreamer that addresses both challenges through two key innovations. First, we introduce a Multi-Expert LoRA Ensemble mechanism that consolidates multiple category-specific LoRA models into a unified representation, achieving superior cross-category generalization while eliminating knowledge interference. Second, building on enhanced semantic understanding, we develop a Cross-View Hypergraph Geometric Enhancement approach that captures structural dependencies spanning multiple viewpoints simultaneously. These components work synergistically: improved semantic understanding enables more effective geometric reasoning, while hypergraph modeling ensures manufacturing-level consistency. Extensive experiments on a custom industrial dataset demonstrate superior semantic generalization and enhanced geometric fidelity compared to state-of-the-art approaches.
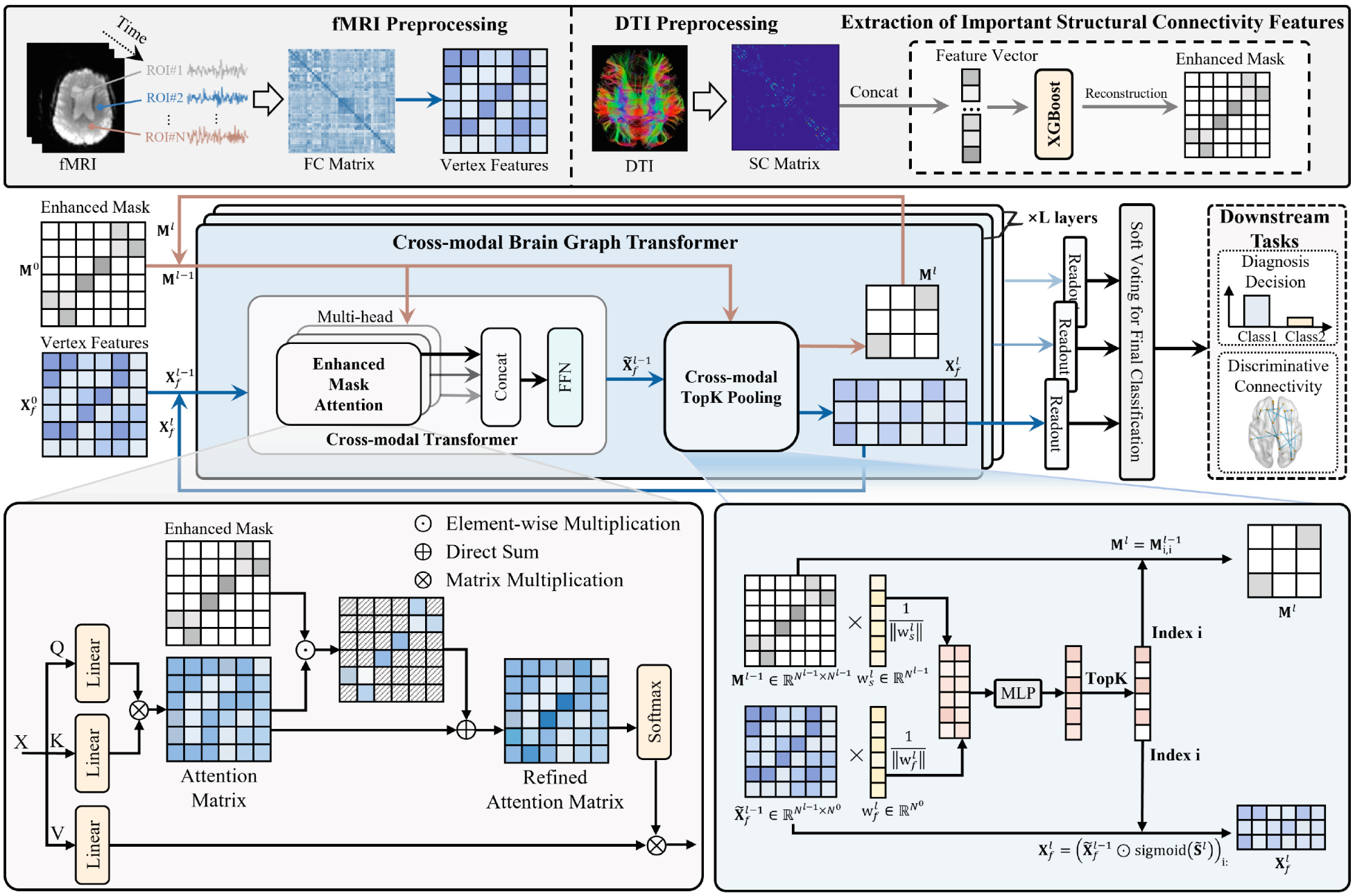
Cross-Modal Brain Graph Transformer via Function-Structure Connectivity Network for Brain Disease Diagnosis
Multi-modal brain networks represent the complex connectivity between different brain regions from both functional and structural perspectives, which is of great significance for brain disease diagnosis. However, existing methods are limited to information fusion in the feature dimension, failing to fully exploit the complementary information between functional and structural connectivity networks. To address these issues, this paper proposes a cross-modal brain graph transformer (CBGT) method for brain disease diagnosis, which also provides an in-depth analysis of coupled function-structure connectivity networks. Specifically, CBGT consists of two main modules: the cross-modal Transformer module enhances the attention mechanism by utilizing structural connectivity features extracted through machine learning methods, capturing long-range dependencies in the cross-modal brain network. The cross-modal topK pooling module combines information from both functional and structural connectivity networks to select significant regions of interest (ROIs) during the reconstruction of the pooled graph, aiming to retain as much effective information as possible. Experiments conducted on the ABIDE and ADNI datasets demonstrate that the proposed method outperforms state-of-the-art approaches. Interpretation analysis reveals that the proposed method can identify multi-modal biomarkers associated with brain diseases.